 |
|
|
|
The Hydra imaging system is based on two core abstractions: a scene abstraction and transformation pipeline, and a renderer abstraction and execution pipeline. Its design goal is to decouple scene processing from rendering, and both from the application, enabling each scene, renderer, or application integration to benefit from other integrations in the ecosystem.
Hydra 2.0's abstractions utilize two central concepts: the scene index which provides a view of a scene and the scene index observer which takes a scene index as input and is informed about scene changes. A filtering scene index (or scene index filter or filter for short) takes an input scene and provides a transformed view of that scene. It is (or has) thus both a scene index observer and a scene index. A scene index plugin bundles one or more filtering scene indices together, and enables runtime discovery and usage of these filters by applications and renderers.
Hydra 2.0 replaces the following legacy Hydra 1.0 classes with scene indices and scene index observers and components built around the scene index API:
Note that the transition from Hydra 1.0 to 2.0 has been happening in several stages:
HD_ENABLE_SCENE_INDEX_EMULATION to false.
USDIMAGINGGL_ENGINE_ENABLE_SCENE_INDEX to false.USDIMAGINGGL_ENGINE_ENABLE_SCENE_INDEX_OBSERVERER_RENDERER to false.HdLegacyRenderControlInterface::GetMaterialRenderContexts), exec does not need to evaluate these networks.A scene in the new API is represented by a subclass of the HdSceneIndexBase interface.
A scene index is responsible for:

The USD scene index, for example, implements a Populate() call by traversing the scene and generating a PrimsAdded notification. It implements change notification in terms of PrimsDirtied. It implements GetChildPrimPaths() by querying the USD prim hierarchy. Finally, it implements GetPrim() by returning the appropriate data for the prim in question (transform, geometric data, etc. as appropriate).
Consumers (such as renderers, the Hydra Scene Debugger, etc) that want to receive notifications from a scene index can subclass the HdSceneIndexObserver interface.
PrimsAdded takes individual prim (path, type) tuples. A PrimsAdded notice can be sent for a prim already in the scene, in which case it should be interpreted as a resync; if the notice has a new type, the prim type should be updated, and all prim data should be considered dirty (as if there were a PrimsDirtied message invalidating the root locator).
PrimsRemoved takes a subtree path, rather than a prim path. Sparse removals can be accomplished by resyncing prims to the empty type.
PrimsRenamed offers a way to rename a subtree, updating all prims under the old subtree to have paths with the old subtree prefix swapped for the new one. This is semantically equivalent to removing the old subtree and adding it in the new location, but provided as a separate notice for optimization purposes since frequently a rename can be handled by updating map keys at much less cost.
PrimsDirtied takes an individual prim path, and a set of locators to datasources. Datasources are the attribute model in the scene index API, and are grouped into a multi-level hierarchy; the locator is a path into that hierarchy. A dirty locator on a prim means that attribute and all child attributes are invalidated. Any caches containing a datasource handle for that attribute or any child attributes need to be cleared and re-fetched.
An important invariant of the system is that the list of prim paths produced by evaluating PrimsAdded and PrimsRemoved messages should match the list of prim paths generated by traversing the scene from the root, using GetChildPrimPaths(). Any prims not reachable by traversal should return an empty prim, with an empty type and a null root datasource.

Prim data is represented by subclasses of HdDataSourceBase or its specializations: HdContainerDataSource, HdVectorDataSource, or HdSampledDataSource.
The basic value datatype of this API is HdSampledDataSource, whose GetValue API retrieves or computes type-erased (i.e. VtValue) data on demand, as with the scene delegate. For attributes with a known type, the subclass HdTypedSampledDataSource<T> can be used. Note that, unlike with the scene delegate, all data access is relative to a shutter offset instead of being part of a separate API.
For a consumer computing the value of a sampled datasource over a time interval (such as a renderer implementing motion blur), GetContributingSampleTimesForInterval() is responsible for providing a set of notable sample times to reconstruct the signal. For cached data, this can return the times where samples are defined, or for analytical motion blur this can return time samples corresponding to a reasonable linearization. If these time samples are used to populate an HdTimeSampleArray, Hydra can linearly re-sample the signal at arbitrary points as required by a renderer. If GetContributingSampleTimesForInterval() returns false, this indicates an attribute that's constant over the shutter window, and the caller should just use GetValue(0).
The intent of this API is for consumers to call GetValue() on either shutter offsets returned by GetContributingSampleTimesForInterval(), or with shutterOffset equal to 0. Defensive code can interpolate or extrapolate other values of shutterOffset, but behavior might be undefined.
Container datasources and vector datasources are both aggregates, and can be used to build up nested structured data. A mesh prim might be represented by a container with a child named "mesh", containing topology and pipeline state, another named "primvars", and others as well, such as transform, visibility, etc.

Here, the light diamonds represent containers and the dark diamonds represent values. Note that containers can have children that are also containers.
The container datasource API introduces GetNames() as a way for downstream code to enumerate which attributes are available. The use of container datasources instead of structs allows for flexibility of representation of similar concepts (e.g. a mesh, a mesh topology) between different renderers which might want to overlay different data on top of the standard points/index buffers.
Named children of a container are retrieved with Get() calls. It's expected that Get() will return something for all of the names defined by GetNames(), and will return null otherwise (but be safe to call). This is useful, for example, if a consumer only wants to check for certain named primvars on a geometry prim, since primvar enumeration at the USD level can sometimes be expensive but it's also lazily deferred to the GetNames() call.
HdDataSourceLocator is the attribute addressing scheme used in DirtiedPrimEntries. Since container datasources can be nested, the locator needs path semantics, where each path entry represents the next container key to query to ultimately end up at the correct datasource. A locator is relative to a root container, which is usually the top-level container datasource representing prim data.
For example, you might expect mesh orientation at: HdDataSourceLocator("mesh", "meshTopology", "orientation");
Locators can identify individual attributes to invalidate, which allows for much more specificity than the HdDirtyBits API. An originating scene can invalidate primvars/displayColor and primvars/displayOpacity separately. However, to capture some of the conciseness of dirty bits, Hydra will interpret the locators in a DirtiedPrimEntry hierarchically, meaning if primvars is dirty on a prim, this implies that primvars/displayColor and primvars/displayOpacity are also dirty.
Datasource aggregations are inherently unstructured, but to transport data from different scenes to different renderers Hydra needs a consensus data format. Rather than encode this format in C++ structs, the scene index API takes a page from USD by separating data storage from schema interpretation. An HdSchema subclass is applied to an HdContainerDataSource and represents what data Hydra expects to find on a container. Any scene index or render delegate that wants to be compatible with the Hydra ecosystem should provide or consume data accordingly. For example, HdMeshTopologySchema corresponds to the HdMeshTopology C++ struct:
Importantly, since the data storage is a container data source, it can transport data not in the schema. If a renderer wants to extend Hydra schemas for renderer-specific data, it can do so, in the above example by sub-classing HdMeshTopologySchema. The schema is just a facade representing the commonly understood structure of a Hydra scene, and all data access is still done through the input container.

See Hydra Prim Schemas for a list of Hydra prim schemas.
One last important API concept arises from the architecture above. It's fairly straightforward to implement a scene index by referring to an input scene index for data access, but then selectively overriding the input scene data. This can be thought of as the lazy programming version of running a transformation on the scene at load time. We call such a scene index a filtering scene index (or scene index filter or just filter for short) and provide a base class for this behavior in HdSingleInputFilteringSceneIndexBase.
This class will register itself as an observer of inputSceneIndex and registers handlers for PrimsAdded(), etc. notices. Note that it's expected to forward these notices appropriately to its own observers. GetPrim() can be implemented with the help of _GetInputSceneIndex()->GetPrim().

These scene index filters are a very powerful architectural tool for decoupling different kinds of scene transformations in a scene or renderer pipeline. See Working With Filtering Scene Indices for additional illustrative examples of scene index filters.
Hydra provides a way to visualize scene data and filters using the Hydra Scene Debugger, available in tools like usdview. You can also add this to your Hydra-enabled application.
As a simple example, let's write a scene index that provides a scene with a single quad.
Multiple scenes can be composed together at the prim and attribute level through the HdMergingSceneIndex. That is, a single prim can have attribute data from multiple input scenes.
You can insert this scene into your application by adding it to the application's merging scene index, see A Hydra 2.0 Application.
scenePathPrefix is the same as the scene delegate ID concept: if your app-native scene has an embedded USD scene at /Path/to/USD, for example, you can set scenePathPrefix = "/Path/to/USD" to re-root the USD data at the new prefix.A more sophisticated scene data implementation with the scene index API would be expected to implement GetChildPrimPaths() in terms of native scene traversal, and implement GetPrim() by conforming native scene data to the Hydra prim schemas as necessary. We've found it very helpful to write an originating scene index that's as simple as possible, and represent complicated scene transformations with filters. As an example of this, UsdImagingStageSceneIndex tries to only handle prim traversal, type lookup, and attribute access. Various scene index filters overlay application state or implement complicated features like instancing resolution:
The flow for UsdImagingStageSceneIndex with these filters looks roughly like this, as of November 2023 (HdRenderIndex is now the application's HdMergingSceneIndex):
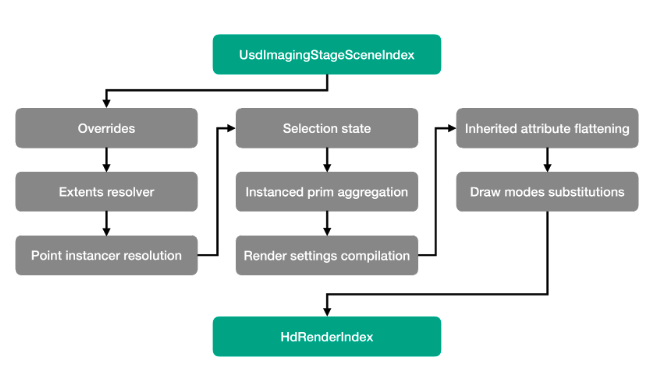
The UsdImaging library provides the method UsdImagingCreateSceneIndices to create a UsdImagingStageSceneIndex and all of its associated filters, and this is the recommended way to create a UsdImagingStageSceneIndex with the correct resolution steps across different USD releases.
For a basic syntactical look at how scene index filters work, the following simple but illustrative examples can be used.
A filter that filters out all cubes from the scene:
A filter that sets the display color for everything to be green:
Note here the use of two utility classes: HdContainerDataSourceEditor and HdOverlayContainerDataSource. These are both useful for doing datasource-level composition, and can recursively merge and combine their inputs (lazily!) as needed.
A measure of caution is required for conditional overrides; due to the PrimsDirtied semantics, if GreeningSceneIndexFilter only overlays data on top of prim.dataSource when _enabled is true, then when the value of _enabled changes GreeningSceneIndexFilter will need to send a dirty message with the root locator, rather than "primvars/displayColor", since the root datasource has changed and we need to notify any listeners (e.g. the flattening scene index) to discard cached copies. A more efficient way to do a conditional override is to unconditionally override the prim datasource, but conditionally override the target datasource, so that only the target datasource needs to be marked dirty.
Another noteworthy utility class is HdSceneIndexPrimView:
For an example of more sophisticated filtering scene indices, there are some core architectural examples in pxr/imaging/hd:
There are also a number of common feature-based scene index filters in pxr/imaging/hdsi:
These filtering scene indices can be inserted into the Hydra pipeline in different ways based on whether they are scenegraph-specific, renderer-specific, or application-specific.
A typical Hydra pipeline has an HdMergingSceneIndex created by the application. This merging scene index also serves as demarcation line between these different filtering scene indices.
Scenegraph-specific Scene Index Filters
Filters that are associated with a specific originating scene graph (like UsdImaging filters that implement USD semantics) can be appended to the originating scene index (e.g. UsdImagingStageSceneIndex) before they are inserted into the HdMergingSceneIndex. As mentioned earlier, UsdImagingCreateSceneIndices can be used to create a UsdImagingStageSceneIndex and all of its associated filters.
Renderer-specific Scene Index Filters
A renderer can define a subclass of HdSceneIndexPlugin, either compiled in the renderer or in an unrelated library. A Hydra application (such as UsdImagingGLEngine) uses the HdSceneIndexPluginRegistry to insert these between the HdMergingSceneIndex and HdRenderer. The order is defined by the scene index plugins through the HdSceneIndexPluginRegistry::InsertionPhase passed to HdSceneIndexPluginRegistry::RegisterSceneIndexForRenderer.
The following example shows a simple scene index filter plugin:
The following plugInfo.json would be used for this example plugin:
Application-specific Scene Index Filters
Application-specific transformations can be added at runtime to the same pool used for renderer-specific transformations. This is especially useful for pipeline tools, which might want to segment the scene in ways that aren't appropriate for other applications.
The following example demonstrates how an app might register an application-specific scene index filter at startup:
It's important to note that the application and renderer-specific scene index filters can be used even if all of the scene data is coming from a scene delegate. Hydra converts internally between the two representations as needed. See Appendix: Scene Index Emulation for details.
The following shows renderer-specific and application-specific filters participating in a scene index filtering workflow (for a Hydra 2.0 application, HdRenderIndex is the application's HdMergingSceneIndex and HdRenderDelegate is an HdRenderer):

The current priority sort algorithm is to run application-specific filters first (in numerical priority order), and then renderer-specific filters (again in numerical priority order).
UsdImagingStageSceneIndex walks a USD stage and dispatches to plugin-based prim adapters that know how to turn a certain USD prim type or API schema into a Hydra prim.
The following is example code for an adapter for a "MyUSDPrim" USD prim and "MyUSDAPI" USD schema.
plugInfo.json for MyUSD library:
MyUSDPrimAdapter.cpp example:
MyUSDAPIAdapter.cpp example:
USD has a concept of multiple-apply API schemas, where the same API schema can be applied to a prim multiple times with different instance names. An example of this is coordinate systems, where applying UsdShadeCoordSysAPI with instance name "foo" adds a "coordsys:foo:binding" relationship to the prim. In these cases, UsdImagingStageSceneIndex will call into the API schema adapter multiple times, one per instance name. Some API schemas (which aren't multiple-apply) won't have an instance name – in these cases, the instance name will be the empty token. Other than the instance name, the API schema adapter API follows the prim API.
Any USD prim will have a base type and an ordered (possibly empty) list of applied API schemas. USD composes attribute definitions on that prim by looking at the base type definition, and then subsequently looking at the API schema definitions in order. This is the process used to determine attribute fallback values, for example. UsdImagingStageSceneIndex matches this by using an HdOverlayContainerDataSource to compose prim data from the base type adapter, and then from each API schema adapter in order. Composition is performed separately for each subprim.

Adapters should route their value-level scene access through the UsdImagingDataSourceAttribute and UsdImagingDataSourceRelationship classes, which handle efficiently retrieving attribute data as well as marking time-variability in the stageGlobals object.
The UsdImagingPrimAdapter is used by both the UsdImagingStageSceneIndex and the legacy UsdImagingDelegate. The API on UsdImagingPrimAdapter used by each, however, is disjoint.
The UsdImagingStageSceneIndex also differs from the UsdImagingDelegate as follows:
The following diagram shows a typical chain of scene indices for an application rendering an image. The chain terminates with an HdRenderer. You can use the Hydra Scene Debugger to explore the scene index chain in detail.
An application can use legacy Hydra 1.0 scene delegates through the HdRenderIndexAdapterSceneIndex.
The USD imaging scene index chain is created through UsdImagingCreateSceneIndices.
The HdMergingSceneIndex serves as demarcation line between the scenegraph-specific scene indices and the renderer- and application-specific filtering scene indices.
The renderer and application plugin scene indices are instantiated through the HdSceneIndexPluginRegistry. The application might also add a caching scene index. We call the scene index that is last in the chain and feeding into the HdRenderer the terminal scene index.
The HdRenderer is created through the HdRendererPluginRegistry and HdRendererPlugin.
By default, HdRendererPlugin::CreateRenderer creates a Hydra 1.0 legacy HdRenderDelegate and wraps it in an HdRenderDelegateAdapterRenderer. However, as the diagram shows, renderers can override HdRendererPlugin::_CreateRenderer for a pure Hydra 2.0 implementation.
A Hydra 2.0-native HdRenderer implementation can use:
The HdsiPrimTypeNoticeBatchingSceneIndex to customize the order in which to update prims based on the prim type.
HdsiPrimManagingSceneIndexObserver instantiates and dirties renderer defined RAII-subclasses of HdsiPrimManagingSceneIndexObserver::PrimBase based on the content and messages from its input scene index. Threading-behavior will be customizable by future input arguments.
Note that there is no pure Hydra 2.0 HdRenderer implementation yet.
A legacy render delegate can already access data from the terminal scene index in two ways:
sceneDelegate->GetRenderIndex().GetTerminalSceneIndex() when overriding HdRprim::Sync, and similarly for HdSprim and HdBprim. Here is an example: This still limits invalidations to those expressible by dirty bits, and still limits data update to the type-sorted-by-tier, thread-per-prim model of HdRenderIndex::SyncAll().
We're planning to maintain the following emulation layers even as we port and deprecate all of our HdSceneDelegate and HdRenderDelegate implementations internally:
Both use the HdDirtyBitsTranslator which encodes the mapping between dirty bits (used in the change tracker) and datasource locators (used in PrimsDirtied()).